Understanding Data Sample
This document provides basic information on data samples and how they are useful when building integration flows.
Data Sample
A data sample is an example of component output data. It is essential in building integration flows, because it allows you to see what sort of data the next component in the flow will receive from the previous one. With this information you can configure the next component to act properly on the input it receives.
You can generate more than one sample from a component. By default, the first one in the list will be used. Also, you can manually select the proper sample from the list. All unused samples will be deleted once you make a choice.
Samples in Integration Flows
Data Sample purposes
Each component in a flow has its own input/output data standards. For proper flow operation, the components need data mapping. It is a process of data conversion from one component’s standard to the next one’s. Basically, data mapper retrieves data from one component and relays it to the next component in a compatible form. In order to see what sort of output data the first component produces we use data sample.
A data sample can be retrieved from a component or written manually by the integrator. In any case, the sample is then given as input to the next component. The receiving component may not require all the data from the sample or may require it in completely different order. That’s when you configure proper mapping so that the receiving component gets input in accordance with its standard.
Please note that samples exist for flow building and testing purposes. Retrieving a sample for an action creates new objects in the target system. If you want to avoid this, you can use Generate Stub Sample function. It retrieves the component’s output template and fills it with fake data that you can discard afterwards. You can also just Skip Sample if you don’t need it. However, we recommend doing this only when you are sure about the data your component will receive.
Handling Large Data Samples
Sometimes there are situations when the size of data sample may be too large and its processing and visualization may take a very long time, which complicates and slows down the debugging of flows. If the data-sample size exceeds 256 KB, the JSON schema generation mechanism is activated instead of real data.

The generated JSON schema is a set of actual keys from the processed object with arbitrary dummy values of the same type as in the used object. As a result, you significantly save time on loading real data and still have the ability to customize the mapping for the next steps.
When the platform replaces real data with the generated JSON schema, a corresponding notification appears in the upper right corner.

Managing Data Sample via API calls
Sometimes it is easier and more convenient to work with the samples not on the platform itself, but by using the corresponding API calls. You can create a data sample, update it or get the specified data sample. To familiarize yourself with this functionality, please read the corresponding section in our API documentation.
Data Sample example
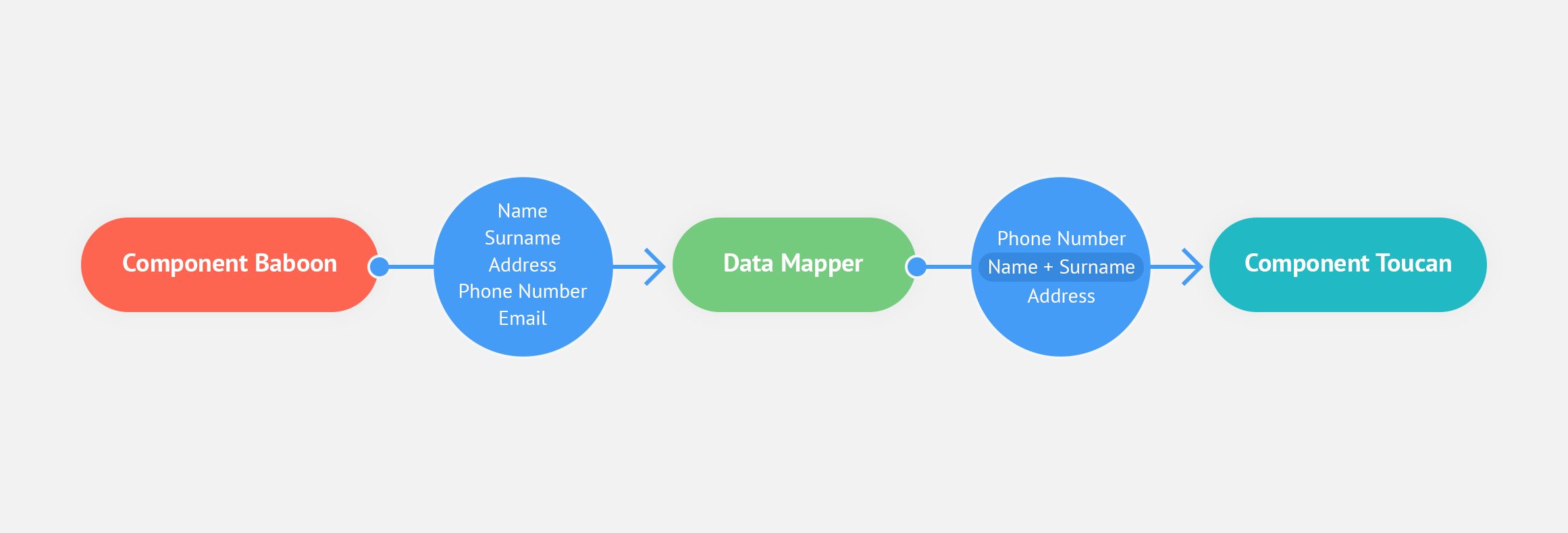
Let’s observe the following process example:
-
Component Baboon is followed by Component Toucan.
-
When we select Component Toucan, we can see what sort of data it accepts as input.
-
By retrieving a data sample from Component Baboon, we can see what sort of data it provides as output.
-
Then we configure the data mapper to relay Baboon data to Toucan, converting it first into a form acceptable by Toucan. The mapping process may include ignoring some of the output fields, switching field places, etc.
-
On the example scheme we can see, that Baboon sends out the following data:
Name,Surname,Address,Phone NumberandEmail. Component Toucan doesn’t needEmail. Also, it hasName and Surnametogether in one field. Data mapper makes the necessary changes into Baboon output, so that the data fits Toucan input standard.